
Mapping the AI Governance Landscape: Pilot Test and Update
AI governance frameworks are multiplying rapidly. Many governments, standards bodies, and companies have released guidelines, principles, and regulations. However, a basic question remains underexplored: what do these frameworks actually cover, and how comprehensively?
To address this, we are building a pipeline to map existing AI risk governance documents to the MIT AI Risk Taxonomy and other relevant taxonomies. We aim to create reports, visualizations, and a database to help users explore the AI governance landscape and understand which AI risks are addressed and which are neglected by current AI governance approaches.
In the first stage of this work, we focus on documents from the Center for Security and Emerging Technology’s ETO AGORA (AI GOvernance and Regulatory Archive), “a living collection of AI-relevant laws, regulations, standards, and other governance documents.” The AGORA dataset currently contains over 950 documents and is growing as new documents are added. If successful, we intend to scale up the pipeline to include other data sources and share all outputs under a Creative Commons license (see Appendix 3).
This document describes the methodology we used to pilot our initial approach and some of our initial findings and feedback.

Systematic Hazard Analysis for Frontier AI using STPA
All of the frontier AI companies have published safety frameworks where they define capability thresholds and risk mitigations that determine how they will safely develop and deploy their models. Adoption of systematic approaches to risk modelling, based on established practices used in safety-critical industries, has been recommended, however frontier AI companies currently do not describe in detail any structured approach to identifying and analysing hazards. STPA (Systems-Theoretic Process Analysis) is a systematic methodology for identifying how complex systems can become unsafe, leading to hazards. It achieves this by mapping out controllers and controlled processes then analysing their interactions and feedback loops to understand how harmful outcomes could occur (Leveson & Thomas, 2018). Weevaluate STPA’s ability to broaden the scope, improve traceability and strengthen the robustness of safety assurance for frontier AI systems. Applying STPA to the threat model and scenario described in ’A Sketch of an AI Control Safety Case’ (Korbak et al., 2025), we derive a list of Unsafe Control Actions. From these we select a subset and explore the Loss Scenarios that lead to them if left unmitigated. We find that STPA is able to identify causal factors that may be missed by unstructured hazard analysis methodologies thereby improving robustness. We suggest STPA could increase the safety assurance of frontier AI when used to complement or check coverage of existing AI governance techniques including capability thresholds, model evaluations and emergency procedures. The application of a systematic methodology supports scalability by increasing the proportion of the analysis that could be conducted by LLMs, reducing the burden on human domain experts.

Assessing Confidence in Frontier AI Safety Cases
Powerful new frontier AI technologies are bringing many benefits to society but at the same time bring new risks. AI developers and regulators are therefore seeking ways to assure the safety of such systems, and one promising method under consideration is the use of safety cases. A safety case presents a structured argument in support of a top-level claim about a safety property of the system. Such top-level claims are often presented as a binary statement, for example “Deploying the AI system does not pose unacceptable risk”. However, in practice, it is often not possible to make such statements unequivocally. This raises the question of what level of confidence should be associated with a top-level claim. We adopt the Assurance 2.0 safety assurance methodology, and we ground our work by specific application of this methodology to a frontier AI inability argument that addresses the harm of cyber misuse. We find that numerical quantification of confidence is challenging, though the processes associated with generating such estimates can lead to improvements in the safety case. We introduce a method for better enabling reproducibility and transparency in probabilistic assessment of confidence in argument leaf nodes through a purely LLM-implemented Delphi method. We propose a method by which AI developers can prioritise, and thereby make their investigation of argument defeaters more efficient. Proposals are also made on how best to communicate confidence information to executive decision-makers.

Scalable AI Incident Classification
A number of AI incident databases exist, but their data is inconsistently structured. I’ve developed a tool to structure AI incident data and presented the results with a dashboard, to help policymakers make evidence-based decisions. The tool classifies real-world, reported incidents by risk category and harm caused, aiming to reveal information about the impacts of AI on society that is currently opaque.
Using an LLM, the tool processes raw incident reports, providing a scalable methodology that could be applied cost-effectively across much larger datasets as numbers of reported incidents grow.
I classified all incidents in the AI Incident Database according to the MIT Risk Repository’s causal and domain taxonomies. I then assigned scores for harm-severity on 10 different dimensions based on the CSET AI Harm Taxonomy, using a scale I developed to reflect impact from zero to 'worst-case catastrophe'.
The outputs are a structured dataset and a dashboard that you can explore through a graphical web interface to identify trends and insights.
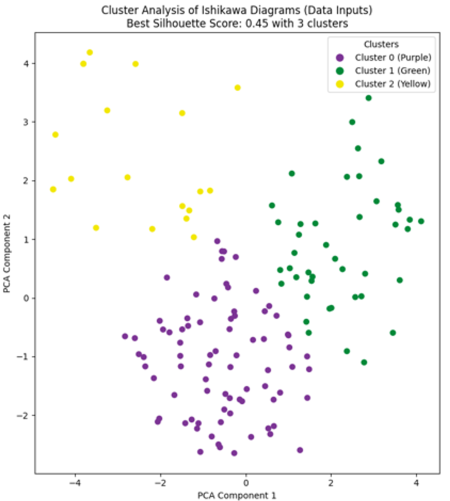
Validity and Clustering of AI Safety Incident Causality Analysis
This article identifies and addresses some shortcomings and potential objections to the original Root Cause Analysis method including reliability and epistemology of responses.
It then describes a cluster analysis of 50 incident reports aimed at identifying correlations between clusters of causes and different types of harm.
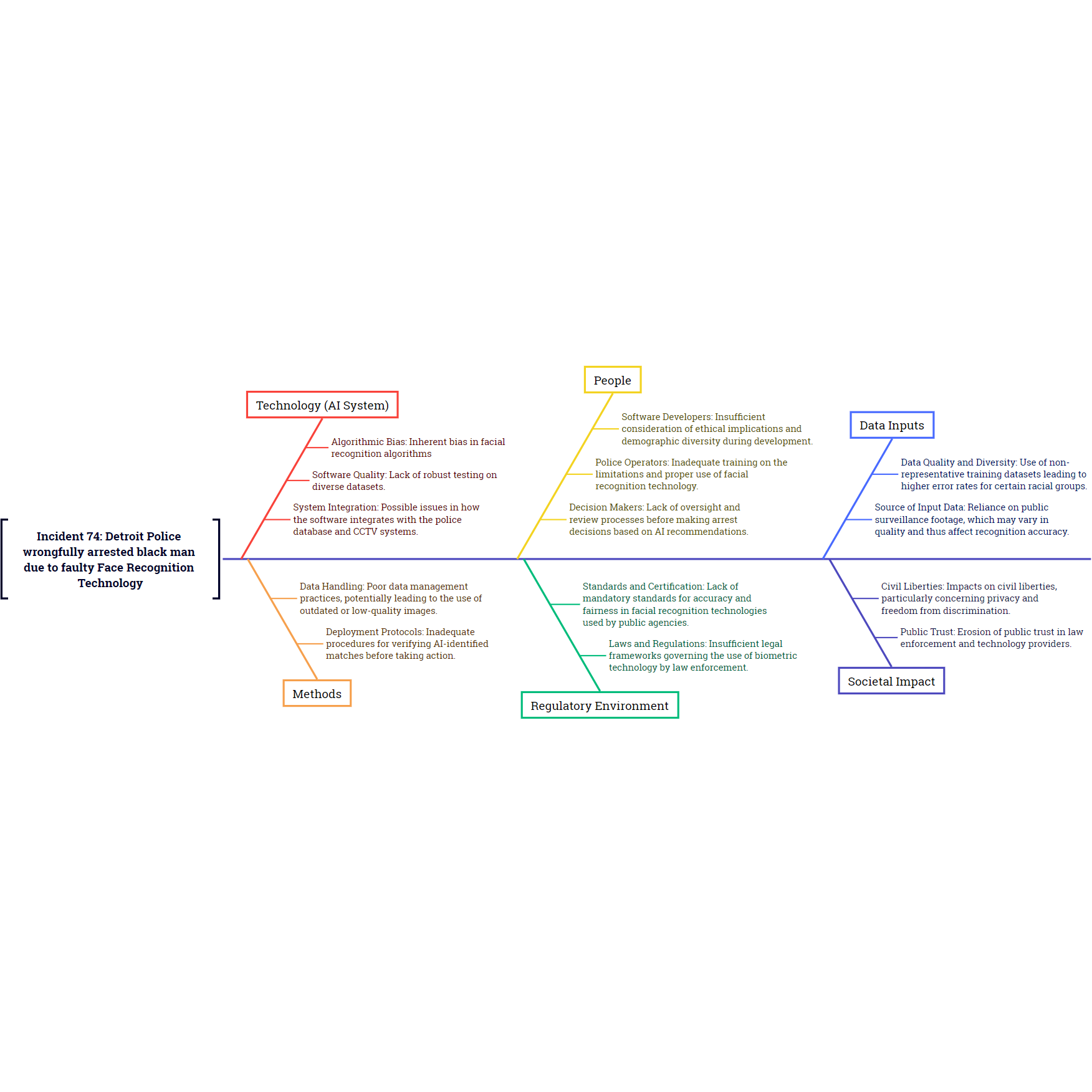
Root Cause Analysis of AI Safety Incidents
The application of Root Cause Analysis tools that are widely used in other areas of engineering could provide insights into the causes of AI safety incidents that would reduce the likelihood of recurrence and support the prioritisation of risk mitigation and harm reduction measures.
This post proposes and demonstrates an approach for using language models to process incident reports and make inferences as to potential causes.
The approach could offer a scalable methodology to aggregate causality data from historic incidents and potentially from modelled future scenarios, in order to contribute to a reduction in the numbers of future safety incidents and the severity of harm caused by them.